Can you tell me what is Apache Spark about?
Apache Spark is an open-source framework engine that is known for its speed, easy-to-use nature in the field of big data processing and analysis. It also has built-in modules for graph processing, machine learning, streaming, SQL, etc. The spark execution engine supports in-memory computation and cyclic data flow and it can run either on cluster mode or standalone mode and can access diverse data sources like HBase, HDFS, Cassandra, etc
What does DAG refer to in Apache Spark?
DAG stands for Directed Acyclic Graph with no directed cycles. There would be finite vertices and edges. Each edge from one vertex is directed to another vertex in a sequential manner. The vertices refer to the RDDs of Spark and the edges represent the operations to be performed on those RDDs
What are the data formats supported by Spark?
Spark supports both the raw files and the structured file formats for efficient reading and processing. File formats like paraquet, JSON, XML, CSV, RC, Avro, TSV, etc are supported by Spark
What is YARN in Spark?
- YARN is one of the key features provided by Spark that provides a central resource management platform for delivering scalable operations throughout the cluster.
- YARN is a cluster management technology and a Spark is a tool for data processing
What can you say about Spark Datasets?
Spark Datasets are those data structures of SparkSQL that provide JVM objects with all the benefits (such as data manipulation using lambda functions) of RDDs alongside Spark SQL-optimised execution engine. This was introduced as part of Spark since version 1.6.
- Spark datasets are strongly typed structures that represent the structured queries along with their encoders.
- They provide type safety to the data and also give an object-oriented programming interface.
- The datasets are more structured and have the lazy query expression which helps in triggering the action. Datasets have the combined powers of both RDD and Dataframes. Internally, each dataset symbolizes a logical plan which informs the computational query about the need for data production. Once the logical plan is analyzed and resolved, then the physical query plan is formed that does the actual query execution.
Explain how Spark runs applications with the help of its architecture.
This is one of the most frequently asked spark interview questions, and the interviewer will expect you to give a thorough answer to it.
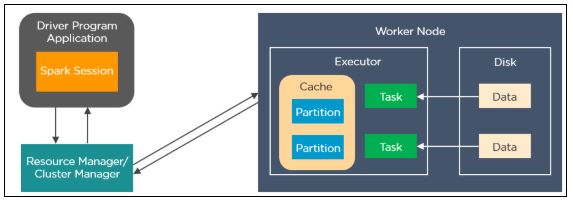
Spark applications run as independent processes that are coordinated by the SparkSession object in the driver program. The resource manager or cluster manager assigns tasks to the worker nodes with one task per partition. Iterative algorithms apply operations repeatedly to the data so they can benefit from caching datasets across iterations. A task applies its unit of work to the dataset in its partition and outputs a new partition dataset. Finally, the results are sent back to the driver application or can be saved to the disk.
What is a lazy evaluation in Spark?
When Spark operates on any dataset, it remembers the instructions. When a transformation such as a map() is called on an RDD, the operation is not performed instantly. Transformations in Spark are not evaluated until you perform an action, which aids in optimizing the overall data processing workflow, known as lazy evaluation.
How can you connect Spark to Apache Mesos?
There are a total of 4 steps that can help you connect Spark to Apache Mesos.
- Configure the Spark Driver program to connect with Apache Mesos
- Put the Spark binary package in a location accessible by Mesos
- Install Spark in the same location as that of the Apache Mesos
- Configure the spark.mesos.executor.home property for pointing to the location where Spark is installed
What is shuffling in Spark? When does it occur?
Shuffling is the process of redistributing data across partitions that may lead to data movement across the executors. The shuffle operation is implemented differently in Spark compared to Hadoop.
Shuffling has 2 important compression parameters:
spark.shuffle.compress – checks whether the engine would compress shuffle outputs or not spark.shuffle.spill.compress – decides whether to compress intermediate shuffle spill files or not
It occurs while joining two tables or while performing byKey operations such as GroupByKey or ReduceByKey
What are the various functionalities supported by Spark Core?
Spark Core is the engine for parallel and distributed processing of large data sets. The various functionalities supported by Spark Core include:
- Scheduling and monitoring jobs
- Memory management
- Fault recovery
- Task dispatching
